Добрый день!
Столкнулись с некоторой проблемой при балансировки grpc трафика в кластер k8s. Сама схема выглядит так:
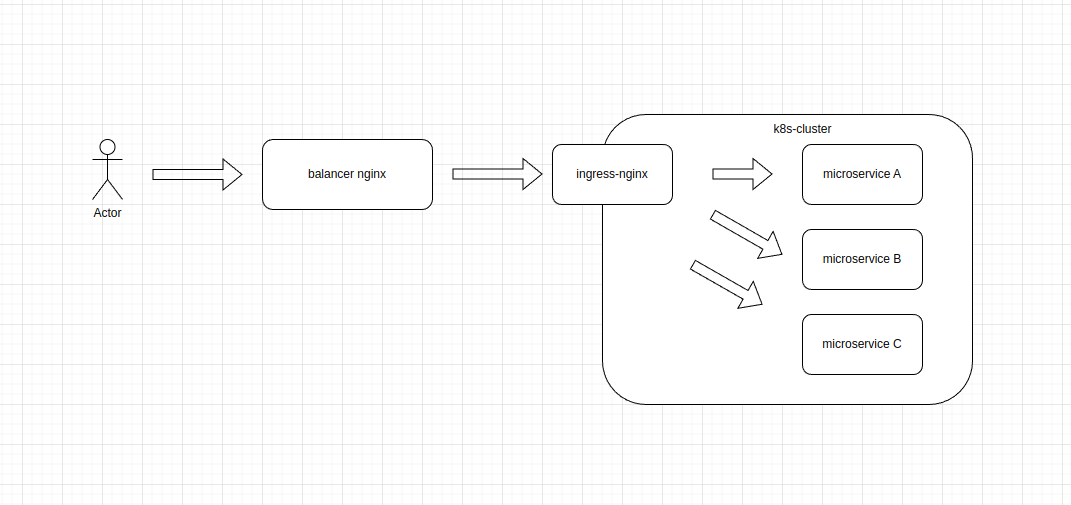
Так как это тестовое окружение, то и кластер k8s всего один.
На балансере nginx схематично настроено следующее
worker_processes auto;
events {
worker_connections 4096;
}
resolver 10.11.12.13 # here is our trust and reliable DNS-server
upstream to_ingress_stage {
zone $server_name.https 1m;
hash $remote_addr;
least_conn;
server the-ingress-test.test.k8s.cluster-stage-el:443 max_fails=3 fail_timeout=15s;
keepalive 15;
}
# default section
server {
listen 443 ssl;
listen [::]:443 ssl;
http2 on;
server_name hello.test.ru;
status_zone $server_name.https;
ssl_certificate /<path-to-ssl-cert>;
ssl_certificate_key /<path-to-ssl-key>;
location / {
proxy_buffers 8 256k;
proxy_buffer_size 256k;
proxy_next_upstream error timeout invalid_header http_504 http_503 http_502 http_500;
proxy_connect_timeout 5;
proxy_cache_use_stale error timeout updating invalid_header http_500 http_502 http_503 http_504;
proxy_ssl_server_name on;
proxy_ssl_name "hello.test.ru";
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header Host $http_host;
proxy_pass_header Set-Cookie;
proxy_redirect off;
proxy_pass https://to_ingress_stage;
}
}
# grpc section
server {
listen 8443 ssl;
listen [::]:8443 ssl;
http2 on;
server_name hello-grpc.test.ru;
status_zone $server_name.grpcs;
ssl_certificate /<path-to-ssl-cert>;
ssl_certificate_key /<path-to-ssl-key>;
large_client_header_buffers 8 256k;
add_header Strict-Transport-Security "max-age=31536000; preload;" always;
add_header X-Content-Type-Options nosniff;
location = /50x-page {
internal;
root html;
try_files /$test_error_page =404;
}
location / {
grpc_buffer_size 256k;
grpc_next_upstream error timeout invalid_header http_504 http_503 http_502 http_500;
grpc_connect_timeout 15;
grpc_ssl_server_name on;
grpc_ssl_name "hello-grpc.test.ru";
grpc_set_header X-Real-IP $remote_addr;
grpc_set_header X-Forwarded-For $remote_addr;
grpc_set_header X-Forwarded-Host $host;
grpc_set_header Host $http_host;
grpc_pass_header Set-Cookie;
grpc_intercept_errors on;
error_page 500 502 503 504 /50x-page;
grpc_pass grpcs://to_ingress_stage;
}
}
Все работало исправно до добавления секции по grpc. Основная проблема - случайным образом возникающие 502е ошибки при запросах к hello-grpc.test.ru. Например, бросаем 2000 запросов при помощи grpcurl - получаем 10 ошибок 502х. Через 10 минут то же самое - 0 ошибок. Опять спустя время - 2 ошибки. Что интересно, для каждой ошибки upstream_response_time и request_time в логе angie равнялись нулю, а в логе ингресс-контроллера этих запросов просто не было(вместо 2000 запросов за период теста в лог попадало только 1990, например).
В качестве приложения использовали стандартный helloworld .
Попробовали направлять запросы непосредственно на ингресс-контроллер, минуя балансер - ошибок не зафиксировали.
Попробовали добавить отдельный апстрим для grpc - и, о чудо! ошибки ушли.
upstream to_ingress_grpc_stage {
zone $server_name.grpcs 1m;
hash $remote_addr;
least_conn;
server the-ingress-test.test.k8s.cluster-stage-el:443 max_fails=3 fail_timeout=15s;
keepalive 15;
}
...
grpc_pass grpcs://to_ingress_grpc_stage;
...
Похоже, что нужно настраивать первый upstream, чтобы не плодить сущностей в конфигурации балансера.
Попробовали увеличить зону разделяемой памяти для upstream
zone $server_name.https 8m;
Не помогло.
Попробовали увеличить число keepalive соединений, и число запросов
keepalive_requests 10000;
keepalive 45;
Не помогло.
Все вместе - и память, и параметры - keepalive, по прежнему, из 2000 запросов некоторый маленький процент 502х ошибок.
Возвращаем второй upstream, и заворачиваем grpc-трафик через него - проблема исчезает.
Вопрос - что еще попробовать при настройке upstream, чтобы он “держал” и обычный трафик, и grpc?